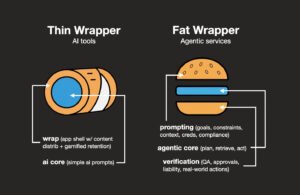
What Changed and Why It Matters
DeepSeek showed that software can outpace scale. They trained on Nvidia’s export-limited H800s and leaned on low-level PTX, not CUDA. The result: high-end performance with fewer GPU-hours than many expected.
This is a signal, not a stunt. AI economics are shifting from “buy more GPUs” to “engineer for constraints.” It also reframes Nvidia’s moat. PTX is still Nvidia territory, but the value is moving up the stack to those who can wield it.
Here’s the part most people miss.
“Efficiency beats funding.”
The Actual Move
- DeepSeek disclosed training details showing they used Nvidia H800 accelerators (a constrained export variant) and drove efficiency with fine-grained code.
- According to The Next Platform’s read of the V3 paper, DeepSeek spent 2.66 million GPU-hours on H800s for pretraining, and a further 119,000 GPU-hours for additional phases.
- Tom’s Hardware reports DeepSeek bypassed CUDA and wrote critical paths in Nvidia’s assembly-like PTX to optimize scheduling, memory, and communication.
“The breakthrough was achieved by implementing tons of fine-grained optimizations and usage of Nvidia’s assembly-like PTX…”
- Community reaction split on what this means for Nvidia demand. Some argue fewer GPUs will be needed; others see demand shifting, not shrinking.
“I’m genuinely confused about why people think DeepSeek hurts Nvidia.”
- Practitioners noted that expert teams already mix inline assembly in CUDA kernels. DeepSeek pushed this further to overcome H800 limits.
“Most of your CUDA kernels have some inline assembly… Deepseek needed to get around CUDA limitations on their lower tier GPUs.”
- On costs, SemiAnalysis challenged the “cheap training” narrative, estimating roughly $1.6B in server CapEx and about $944M to operate such clusters, underscoring the true capital intensity.
“Total server CapEx for DeepSeek is ~$1.6B, with a considerable cost of $944M associated with operating such clusters.”
- Multiple explainers framed the move as a software-first disruption, with claims that DeepSeek’s models rival frontier systems on efficiency and quality.
The Why Behind the Move
DeepSeek optimized around constraints. Export controls limited hardware. So they redesigned the stack to squeeze more from each GPU-hour.
• Model
Architected and scheduled for H800 realities: bandwidth limits, memory pressure, and communication overhead. Critical kernels hand-tuned in PTX.
• Traction
The approach sparked wide technical attention. Builders are now asking: how much performance sits on the table in our kernels and comms?
• Valuation / Funding
No specific raise disclosed in the sources. But the cluster scale and operating costs suggest institutional-level capital and long-horizon bets.
• Distribution
Publishing techniques and numbers accelerates mindshare. The real distribution loop is talent magnetism: engineers want to work where the hard problems are solved.
• Partnerships & Ecosystem Fit
PTX work binds them tighter to Nvidia silicon, even while “bypassing CUDA.” It’s not anti-Nvidia. It’s deeper Nvidia.
• Timing
Export controls forced frugality. The moment rewarded teams that engineered for constraints rather than waiting for better chips.
• Competitive Dynamics
- Efficiency raises the bar. You now compete on systems design, not just parameter count.
- If others adopt similar kernels, the unit cost per capability drops industry-wide.
- This can expand the market faster than it reduces hardware demand.
• Strategic Risks
- PTX is Nvidia-specific. Portability and maintenance burdens are real.
- Reproducibility: bespoke kernels can be fragile across drivers and generations.
- Cost narratives invite scrutiny; make sure your accounting is apples-to-apples.
What Builders Should Notice
- Efficiency is a strategy. Treat GPU-hours like runway, not a sunk cost.
- Co-design wins: model, data pipeline, kernels, and network must be tuned together.
- CUDA is not the ceiling. PTX-level work can reclaim double-digit gains.
- Constraints clarify architecture. Design for the bottleneck you have, not the chip you want.
- Publish your methods. Clear technical artifacts compound talent and distribution.
Buildloop reflection
“The next moat isn’t bigger models. It’s fewer wasted cycles.”
Sources
- Medium — How DeepSeek Cracked Nvidia’s Monopoly (and Why …)
- The Next Platform — How Did DeepSeek Train Its AI Model On A Lot Less
- Reddit — DeepSeek’s AI breakthrough bypasses Nvidia’s industry- …
- Hacker News — Ask HN: Confused about how DeepSeek hurts Nvidia
- Mroads — DeepSeek: The Complete Guide to AI’s New Game- …
- Tom’s Hardware — DeepSeek’s AI breakthrough bypasses industry-standard CUDA, uses assembly-like PTX programming instead
- SemiAnalysis — DeepSeek Debates: Chinese Leadership On Cost, True …
- LinkedIn — DeepSeek – A Deep Dive into Efficiency and Innovation