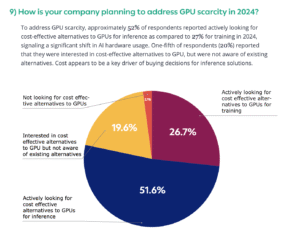
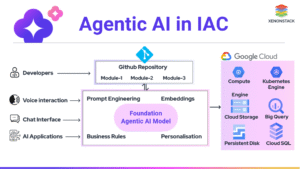
What Changed and Why It Matters
AI is moving past a single-vendor narrative. The constraint isn’t just access to Nvidia GPUs anymore. It’s end-to-end efficiency across models, data, software, and heterogeneous hardware.
Demand keeps outpacing supply. Teams can’t wait for perfect chips. They’re optimizing everything: architectures, training recipes, inference stacks, and deployment patterns.
The center of gravity is shifting from raw compute to smarter compute.
This changes who wins. Not only GPU-rich incumbents—but the builders who squeeze more capability per dollar, per watt, and per minute.
The Actual Move
Here’s what the ecosystem is doing right now:
- Diversifying accelerators. Hyperscalers and enterprises are evaluating and deploying non‑Nvidia options alongside Nvidia, including cloud TPUs and custom silicon, to balance cost, availability, and performance.
- Re-architecting models. Teams are embracing mixture‑of‑experts, quantization, pruning, and distillation to cut inference cost without giving up quality.
- Tight data loops. Better data curation and retrieval reduce token waste and context length, shrinking latency and spend.
- Software-first efficiency. Compilers, graph optimizers, and runtime schedulers are becoming core IP—often beating hardware swaps on ROI.
- Edge and on‑prem resurgence. NPU-equipped devices and compact models push real-time inference closer to users and sensitive data.
Most gains now come from system design, not a single breakthrough chip.
The Why Behind the Move
AI is entering its efficiency era. Here’s the builder lens.
• Model
Smaller specialist models and MoE unlock higher throughput. Quantization (often 8‑bit to 4‑bit) preserves quality while slashing memory and cost.
• Traction
Latency and reliability win users. Efficient routing, retrieval, and caching lift perceived speed—often more than bigger models do.
• Valuation / Funding
Infra spend is massive, but capital wants operating leverage. Efficiency turns burn into margins.
• Distribution
Clouds push managed stacks tied to their silicon. ISVs win by abstracting hardware and standardizing MLOps across mixed fleets.
• Partnerships & Ecosystem Fit
Chipmakers, clouds, and software vendors co-design stacks. The moat is the integration surface: drivers, compilers, kernels, and tooling.
• Timing
Training headlines fade; inference economics decide adoption. The next 12–24 months reward teams that ship fast, cheap, and reliable.
• Competitive Dynamics
Nvidia leads, but the field is widening. Heterogeneous fleets are the default; portability and performance parity are the asks.
• Strategic Risks
- Vendor lock‑in via opaque toolchains
- Quality regressions from aggressive compression
- Fragmented observability across mixed hardware
- Governance and safety debt as deployments scale
What Builders Should Notice
- Efficiency is a product feature. Measure and market it.
- Heterogeneous is normal. Design for portability from day one.
- Data beats params. Curate, retrieve, and cache with intent.
- Compilers are leverage. Treat runtimes as core strategy, not plumbing.
- Edge is back. Right-size models to where the user and data live.
Optimization is now a go-to-market strategy.
Buildloop reflection
“AI’s next winners won’t just train bigger—they’ll ship smarter.”
Sources
- Boston Consulting Group — The Race for Advanced AI Chips