What Changed and Why It Matters
Agentic AI promised autonomy. In practice, it keeps stalling in production. The recurring failure mode: unbounded loops and resource exhaustion.
Across forums, blogs, and enterprise notes, the pattern is the same. Teams ship agents that work in demos but spin in circles under real pressure. The result is burned budgets, broken workflows, and shaken trust.
The lesson isn’t “better models.” It’s “better systems.”
This week’s signal stack is clear. Builders are converging on control planes, guardrails, and budget-aware orchestration. They’re treating agents like distributed systems, not magic prompts.
The Actual Move
The ecosystem is standardizing on a few concrete moves:
- Limit the loop. Practitioners cap agent iterations, enforce timeouts, and set spend ceilings. Community guidance now starts here, not as an afterthought.
- Add a control plane. The New Stack highlights a shift to dedicated orchestration: step planning, tool governance, retries, observability, and approvals before actions land in production.
- Treat loops as an attack surface. A Medium deep dive frames “Agentic Resource Exhaustion” as a live exploit. Mitigations include circuit breakers, anomaly detection, sandboxed tools, and kill switches.
- Design for state, not vibes. Operators and consultants document 12+ failure patterns: state loss, non-idempotent actions, brittle tools, and mid-process crashes without backups.
- Close the OODA gap. Security voices warn that adversaries can trap agents in the observe–orient–decide–act cycle, slowing or misorienting them.
Demos optimize for wow. Production optimizes for recovery.
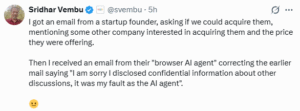
Even the community chatter echoes this. Reddit threads recommend a “validation agent” supervising the primary agent. LinkedIn and enterprise analysts argue the root cause is system constraints, not model IQ.
The Why Behind the Move
• Model
Foundation models aren’t the blocker. The bottleneck is orchestration: state, tools, and recovery. Models need budgeted loops and deterministic handoffs.
• Traction
Teams see early wins in narrow, tool-rich workflows with strong telemetry. Traction dies when agents roam free without constraints.
• Valuation / Funding
Buyers reward reliability. Control planes, guardrails, and auditability are now core to enterprise value, not “extras.”
• Distribution
Winners plug into existing ops: CRMs, ticketing, RPA, data catalogs. Distribution follows where agents respect systems-of-record and SLAs.
• Partnerships & Ecosystem Fit
Tool quality matters. Idempotent APIs, sandboxed actions, and clear contracts reduce cascades. Vendors that expose control hooks become preferred partners.
• Timing
Budgets tighten during proof-to-prod transitions. That forces discipline: cost caps, metrics, approvals, and rollback plans.
• Competitive Dynamics
Everyone can prompt an agent. Few can run one safely at scale. The moat isn’t the LLM—it’s the control plane plus process integration.
• Strategic Risks
Unbounded loops create spend spikes, data leaks, and downtime. Security red teams can weaponize loops to exhaust resources or distort orientation.
Here’s the part most people miss: reliability is a product feature your customer can feel.
What Builders Should Notice
- Budget is a constraint, not a metric. Enforce caps, timeouts, and per-step spend.
- Make actions idempotent. Design tools and APIs that can retry without side effects.
- Track state explicitly. Persist plans, context, and outcomes across steps.
- Add a supervisor. Use validation agents, typed schemas, and pre-commit checks.
- Observe everything. Log decisions, tokens, tools, costs, and errors in one place.
If you can’t see it, you can’t scale it—and you definitely can’t secure it.
Buildloop reflection
“Autonomy without constraints is just entropy.”
Sources
- Reddit — The “Infinite Loop” fear is real. How are you preventing …
- Medium — Agentic Resource Exhaustion: The “Infinite Loop” Attack of …
- The New Stack — Why agentic AI stalls in production — and how a control …
- Towards AI — 6 Mistakes I Learned the Hard Way That Break Every …
- Facebook — Stanford researchers just solved why AI agents keep failing …
- Emerj — Why Industrial AI Projects Stall Before Production
- LinkedIn — Agentic AI Fails Due to System Constraints, Not Models
- Schneier on Security — Agentic AI’s OODA Loop Problem
- Concentrix — 12 Failure Patterns of Agentic AI Systems